Feel free to download and use any of this, but please don't use it without crediting me.
For the interested: my resumè .
The Ruby Kerberos C extensions plus Ruby code archive is part of a survivable, distributed proposal/bid system. This system demonstrates authenticated (using Kerberos 5) event type messaging over an IPv4 network. This system currently works only on Linux, but it would be easy to port to other systems that have BSD style socket support.
While an early version, and a bit buggy, it serves as a useful example of Kerberos V programming, said examples being fairly rare, in my experience. I later decided to go with UDP instead of TCP and re-implemented that way.
The background.py Python program is only useful to Linux users who run GNOME, though the code that sets a picture as a background image is quite localized, and if your OS has a similar interface, the code should be easily hacked for your platform.
TriePy is a C based extension module that addes Trie support to Python. Read the notes about where, how and why to use this instead of other containers.
The LinkedList gzipped tar archive contains a simple linked list program that builds a linked list, prints it out, reverses it, and prints it out again. This was written in response to a company blog that claims that the majority of programmers they interviewed couldn't perform such a simple task. I suspect that they are greatly exaggerating. They raise an important point, though. Most interviews are pretty worthless.
The Sudoku thing is kind of fun, but not quite complete. To finish it off good an proper, I should add a brute force search technique to finish solving puzzles that are not quite valid, or that require constraints not coded in yet.
The BLE implemented as a data flow operation was given to me as a problem to solve. How do you implement a BLE instruction (that's a branch if less than or equal for those of you who don't do assembly) with only the OR, AND, SHR, SUB, PUSH and POP instructions, where the PUSH and POP can be used to push or pop the instruction pointer?
The X11 hello program was written to demonstrate just how small an X11 program can be.
The Python hex drawing programs are small, designed to do something very simple and straight forward in the minimum amount of code. They are not object oriented nor particularly reusable because they are one offs. They do demonstrate how to write Postscript, though.
Because some of the programs here are raw and simple, I included the binary trie template container to show my professional C++ work. I also used it as a class example when I taught an advanced software engineering course.
The Java StringTrie generic is useful in that it efficiently supports prefix constrained slices of the container contents. There are many uses for such a capability, including association containment.
The C# Expect package basically re-implements a minimal version of Expect in C#. The interesting thing about it is that it demonstrates the use of custom attributes and reflection.
The ObjC-Maze package draws single solution mazes. This program was used in an advanced software engineering course to demonstrate several aspects of object oriented programming. It is also kind of fun for kids who like to solve mazes, and it can create both TeX and Postscript output.
The dynamically allocated 2D array thing is an answer to yet another interview puzzle. There are two implementations, one constrains the lowest (number of columns) array bound at compile time, the other allows for any dimensionality, but requires that management information be created and maintained. The second really begs for an object oriented implementation.
The Fixed Array stuff is yet another interview programming assignment. So much for programmers having portfolios. I thought it was a good idea, but I guess not.
The Binary Tree checker program is yet another interview question, one that I flubbed due to time constraints (and not having worked with binary trees for, like, ever . . . does anybody still use this data structure?) but it is interesting because, expanded just a step past the interview question, it can check sub-trees below invalid nodes. Is that a useful property? Well, yeah, I've run into a few situations where that would have been handy.
So you are looking for a Master Carpenter to create for you a unique, hand crafted armoire for your new master bedroom.
When you interview the available choices, what is the first thing you ask them? Is it, "How many years of experience do you have working with Craftsman tools?" If they say "none", do you pass on them?
The software industry has always treated knowledge as if it was the same as talent, yet these are two very different things.
At one of my very first interviews after I had graduated college, I was quizzed on my knowledge of C. I was hired because my interviewer was impressed with my knowledge, saying that I was able to answer questions that people with years of experience could not.
I had exactly four days experience with the C at the time of the interview, having just picked up the book the day my friend told me about the open position.
At my most recent position, I was hired by a manager who knew I had never even seen any PL/SQL code. He dropped a book on my desk confidently assuming that I would come up to speed quickly.
Two days later (and only a small part of those two days were spent learning PL/SQL) I was turning out code. By the end of a week, I had completed my first production quality package. In a month's time, I was helping others write better PL/SQL, and guiding them in finding the right packages to use to solve problems.
So, what is the first thing that you see when scanning the job listings? A laundry list of a minimum number of years with specific tools, that's what.
A person with a computer science degree and a demonstrated talent for computer science should be able to learn new tools within days, because all screwdrivers are functionally the same, just as all web application programming toolkits are the same. It is only the colors and sizes of the handles that vary.
So here we are, with all these storage options. Direct attach, distributed file systems (NFS and CIFS), iSCSI for cheapskates, Fiber Channel for the guys who have too much money, Firewire and USB.
Add on top of that blade systems, virtualization, netbooks, laptops and cell phones, and what do you have? You have an opportunity to do hardware as a service.
Hardware as a service is simply an upscale, modernized version of the old, old service center concept where you rented time on a time share service, but did not own the machine. Modernized means that a cell phone owner could buy "hardware" as a service and have it made available to them over the network, with their cell phone being the equivalent of a smart X terminal.
For now, the idea of managing processing resources is on hold in SARM. While eminently feasible, I'm more interested in leveraging the wealth of network transparent storage solutions to perform storage management.
Fundamentally, SARM is designed to manage storage resources in an intelligent, policy constrained, automated fashion. It should be sufficient to simply tell a consumer that a new application or service is being started on the enclosure that the consumer is responsible for, answer some questions that define the human imposed constraints on the application, then let SARM do the storage provisioning, maintenance and administration.
The storage area part of SARM is that set of storage resources that has been added to the storage area.
The nature of direct attached storage forms the core of the user's expectations. Direct attached storage is private, in that it is secured by being resident within the computer enclosure it is attached to.
The operating system secures access to the storage from the software perspective, while the enclosure acts as a security boundary, preventing people who don't have access to the inside of the box from eavesdropping on the data flowing across a SCSI or ATA bus.
So to create the equivalent user expectations, security is fundamental to the proper design of SARM. To that end, Kerberos 5 is the base security system. All of the distributed components of the SARM software use and require Kerberos 5. The Kerberos domain becomes the virtual enclosure, and Kerberos encryption services will be used to secure command and control messages.
In effect, the Kerberos domain becomes the virtual enclosure of the storage area.
While Kerberos can create a virtual enclosure, and ensure the privacy of C-n-C messages, IPSec will be required to produce the equivalent of a virtual enclosure around the transport of DFS, netblock and iSCSI data. This will be absolutely necessary if/when a cell phone or netbook user mounts a block device on their cell phone using iSCSI over the Internet!
All storage resources are, at the level of the device, still direct attached to some kind of computer. In almost every case, the storage is attached to a system that can do at least minimal computing. This storage comes in so many different forms as to require at least a simple method for describing the various constraints of each piece.
Different kinds of direct attach storage busses (SCSI, SAS, USB, USB2, FireWire, and ATA) have different host bus adaptors, which require different kinds of management and that constrain the use of the attached storage in different ways.
Combine different total size, speed, block size and underlying operating systems with different kinds of storage composition techniques such as logical volume management, RAID and multi-level RAID and software RAID with different kinds of backup and replication technologies, and you have a fairly interesting set of constraints that describe just storage itself, and in many different (system specific) ways.
To help model all of this, we need a relatively simple but fairly abstract set of classifiers. The classifiers that the SARM project is based on are:
The contract classifier is basically a container for storage constraints on the one hand, while the bid is a response to the contract, and on the storage producer side, a second container full of abstract storage resources is maintained that has an association to the contract. These resources satisfy said constraints.
Unlike more naive designs, the concrete details of storage are never described nor passed to the consumer. It is simply unnecessary to do so, as one of the primary advantages of SARM is obviated if storage provisioning can't be adequately described in the implemented contract and bid scheme.
More importantly, the system can't automatically manage resources if it can't automatically manage resources. In other words, this tautology demonstrates the simple failure of the design: If the system isn't doing a good enough job on its own tack, and needs human intervention at a low level, it has failed its design purpose.
SARM will, eventually, supply a number of services. The most important service will be the ability to automatically provision the best available storage in a storage area for use by an application or service. Other services are, however, quite useful and include such things as data redundancy, automatic migration of data from one producer to another when the resources of an area change due to planned or unexpected events, the quick and automatic recovery of an application or service in the event of a storage failure event, the ability to assign and then quickly re-assign not just virtual, but physical hardware using PXE boot and iSCSI or netblock root, to name just a few.
A collection of blades, combined with SARM and especially PXE boot and iSCSI root would allow hardware as a service to compete with virtualization as the most efficient technique for assigning various resources to current need. More-over, this technique would allow for hardware to be sold as a service to remote terminal users, such as netbook and cell phone users.
Obviously some work needs to be done in this area, but the technologies already exist (suspend and/or hibernate on laptops) to quickly reassign hardware (hibernate to iSCSI disk, then reassign the blade to another iSCSI disk and wake up that machine image) in a way similar to task switching in today's modern OSs. The advantages of having the use of more powerful computing resources through the interface of a cell phone are obvious, but even if the cell phone user chooses not to buy processor cycles (to rent a blade for an hour or two) the use of IPSec and iSCSI would allow the cell phone user to greatly expand the size of their storage pool while simultaneously out-sourcing the administrative tasks of backup and recovery. All this without adding to the size or bulk of their phone.
SARM is designed around the core concepts of security and safe failure. To that end, SARM is based on a secured event messaging system (a very early version of this can be found above in my Simple Programs collection).
Being events, these messages are asynchronous in nature. Thus, if part of a SARM domain goes quiet, it doesn't bring down the whole domain. Just as importantly, event type messages allow for simple, widely dispersed parallelism. In extreme cases, a contract can be put out to the domain for bid by simply broadcasting the contract event message and parameters.
More likely the consumer/producer sets will use some kind of call-tree method, especially in light of the fact that SARM specifically and explicitly supports sub-divided storage areas, but even in that case the efficiencies of mass-distributing a contract so that individual producers can attempt to satisfy its constraints nearly simultaneously is obviously more scalable and more efficient than a serial, call-and-return, synchronous approach.
I've got the authenticated, encrypted event messaging support modules for Ruby working (albeit a few bugs in the cleanup need to be quashed to fix a file descriptor leak) and the basic contract/bid design working with some basic testing having already been performed.
What's next is to expand the hardware abstraction layer just a bit and do some more work on querying the storage of a Debian Linux box. Linux storage description facilities are truly primitive, but there seems to be just enough information to do a basic description. What is sadly lacking is any ability to query the hardware RAID systems, as well as the total lack of facilities to configure a hardware RAID system.
But Linux is free, as is every bit of the enabling software (iSCSI, NFS, Samba, DHCPD version 4, Ruby and the C compiler, to name just a few) that I need, so there you have it. Besides, Debian's package management system will come in very handy when it is time to implement the auto-install capability.
What about it? SMI-S is mostly a network transparent, abstract direct attached storage description system that has truly abysmal security.
It is, in effect, at the same level in SARM as the Linux command line utilities that SARM uses to query direct attached storage. Eventually, when SMI-S is mature enough and wide spread enough to be required, the storage producer daemons will probably use it to manage the storage on enclosures in pretty much exactly the same way as the producer daemons will manage direct attached storage on the machines they are running on.
No big deal, in other words, except for the gaping security hole, which I sincerely hope will be plugged by then.
I've already used an early version of this (minus the security stuff) to do a proof of concept, as well as test the usability of diskless workstations in my home. Works fine, though I learned three things very quickly:
Not long ago, a good friend presented me with an interesting tiling problem. The problem is relatively easy to describe:
Take an integer number, n, greater than 3. Create a set of tiles for each integer number, from 1 up to n. Each tile i has the property of being exactly i + 2 boxes in length, where the first and last box of each tile contains the number i. Thus, the complete set of tiles for n = 4, where the empty box is represented by a # character, is:
1#1
2##2
3###3
4####4
The problem is to pack these tiles into a vector that contains exactly 2 x n spaces. The tiles can (and, indeed, must) overlap. The rule is that empty boxes in each tile can be filled by the boxes in the other tiles that contain numbers. Thus the problem is to fill each of the empty boxes in each of the given tiles with a numbered box from some other tile. If the box into which to pack the 4 tiles given above is 2 x 4 = 8 boxes long:
########
then one possible solution for the 4 tile problem is to pack them into the 8 box space using these four operations::
As is probably obvious, the order in which the tiles are packed into the solution space is not relevant to finding a solution, so solutions are usually presented as simple strings of numbers. The two solutions to the four tile problem are:
These two solutions are obviously mirror images of each other, but for the purposes of this problem, we will accept mirror images as separate solutions.
While finding solutions for four tiles is relatively simple, the problem becomes much more difficult with larger numbers. More importantly, and more interestingly, certain values of n do not seem to be amenable to solution. There do not, for instance, appear to be solutions for the 5-tile and 6-tile sets, though there are solutions for the 7 and 8 tile sets.
The friend who presented me with this problem managed to find, by hand, a solution for the 8-tile before he presented the problem to me. As a computer scientist, I responded as computer scientists are wont to do: I wrote a program to solve the problem.
The program I wrote to solve this tiling problem is interesting in that it illustrates the use of genetic algorithms (GA's) to solve difficult problems. GA is a computer simulation of evolution, so for all intents and purposes, this program uses evolution to demonstrate a weakly human intelligence competitive ability to solve a difficult problem.
For those interested in GA's (this program uses Messy GA, Over-specification, Mutation, Deletion, Fusion, One Point Crossover and Reordering), the source code is available in a zip archive. The source should compile and execute on any POSIX compatible platform, but I've only actually tried it on two versions of Unix. The source code should be considered to be in the public domain, and you are free to use or abuse it as you see fit.
Let there be no confusion: I know the problem is more efficiently and quickly solved using a brute force technique. I wrote a program to do that. I just wanted to play around with messy GA's, OK?
Take a set of eight balls, seven of which weigh exactly the same, the eighth weighs noticeably more.
Using a balance, find the heavier ball while only using the balance twice.
Hint: This is a three value logic problem.
Take the sequence of integers numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9 and place them into a 3x3 square, using every number in the sequence only once. Describe an algorithm for deciding which numbers go where such that all eight vectors (all columns, all rows and both diagonals) add up to the same number.
Answer:
The first thing to note is the symetry around the middle number:
| Pair 1 | Pair 2 | Pair 3 | Pair 4 | Pivot Point |
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 |
| + 9 | + 8 | + 7 | + 6 | |
| = 10 | = 10 | = 10 | = 10 | 10 + 5 = 15 |
Add all the columns, and you get the same number: 10. That, added to five, gets you a sum of fifteen on four of the eight vectors.
Note that adding two numbers to the number nine to get 15, or adding two numbers to the number one to get 15 are the most constrained actions that can be taken.
| 15 | - | 9 | = | 6 |
| 15 | - | 1 | = | 14 |
Of the remaining six numbers (one must be across from nine so that 1, 5 and 9 are in a vector to get 15, and we can't use any number more than once), only two other numbers add up to 6: 4 and 2.
As a cross check, of the remaining four numbers, only two add up to 14: 6 and 8.
Since only two numbers of the remaining six can be added to nine to get fifteen, that tells that nine must be in a center square on one of the four sides. If nine were placed in a corner, there must be three pairs of numbers that, added to nine, make 15. This gives us the ordering of a side, and because we already know the opposite number from above, we get:
| 6 | 1 | 8 |
|---|---|---|
| x | 5 | y | 2 | 9 | 4 |
The remaining pair of numbers can be placed in the array in only two ways. To determine the proper locations, add the two numbers in either column that contains an x or a y, subtract that sum from 15, and that is the number of the remaining pair that belongs in that cell: 15 = 8 + 4 + y. Y is three, so the answer is:
| 6 | 1 | 8 |
|---|---|---|
| 7 | 5 | 3 | 2 | 9 | 4 |
An interesting fact about Fibonacci series is that a series pair, treated as multipliers based on their numeric location in the set, can be used to calculate the value of the series at that offset higher or lower in the series.
Fibonacci Series:
| Increment | F0 | F1 | Value |
|---|---|---|---|
| 0 | 1 | 1 | = 2 |
| 1 | 1 | 2 | = 3 |
| 2 | 2 | 3 | = 5 |
| 3 | 3 | 5 | = 8 |
| 4 | 5 | 8 | = 13 |
| 5 | 8 | 13 | = 21 |
| 6 | 13 | 21 | = 34 |
| 7 | 21 | 34 | = 55 |
| 8 | 34 | 55 | = 89 |
| 9 | 55 | 89 | = 144 |
| 10 | 89 | 144 | = 233 |
| 11 | 144 | 233 | = 377 |
| 12 | 233 | 377 | = 610 |
| 13 | 377 | 610 | = 987 |
| 14 | 610 | 987 | = 1597 |
| 15 | 987 | 1597 | = 2584 |
| 16 | 1597 | 2584 | = 4181 |
| 17 | 2584 | 4181 | = 6765 |
| 18 | 4181 | 6765 | = 10946 |
| 19 | 6765 | 10946 | = 17711 |
| 20 | 10946 | 17711 | = 28657 |
| 21 | 17711 | 28657 | = 46368 |
| 22 | 28657 | 46368 | = 75025 |
There are two ways to find the value of the the Fibonacci series three or four steps farther along, and that is to either iterate through those three or four sets of operations, or if the difference is within the limits of the above table, you can multiply the current Fibonacci series pair by the pair at the step value difference from the table, then add them together.
Example:
If your pair is 3, 5, which add to 8, then to find the value of the function two steps down the series, multiply 3 and 5 by 2 and 3 (the pair shown at increment value 2 in the table) and add them together:
3 × 2 + 5 × 3 = 21
If you find 3 and 5 in the above table, then look down two rows, the value shown is 21.
This can be proved by deduction by simply substituting the Fibonacci series function into itself, then observing the factors. If you start with:
F2 = F1 + F0
The next is:
F3 = F2 + F1
Substitute the first equation into the second to get:
F3 = ( F1 + F0 ) + F1
Simplify to get:
F3 = 2 × F1 + 1 × F0
The factors of 2 and 1 are shown for increment value 1 in the above table.
The obvious advantage of this technique is that to calculate the Fibonacci series value of a large step in the series all you need to do is a single table lookup, two multiplies and a single addition.
The obvious disadvantage is that the result is that of the Fibonacci function, it does not get you the Fibonacci pair that lies in the series to give you that value, and thus this technique can't be used successively.
Unless you do it twice, of course. :-)
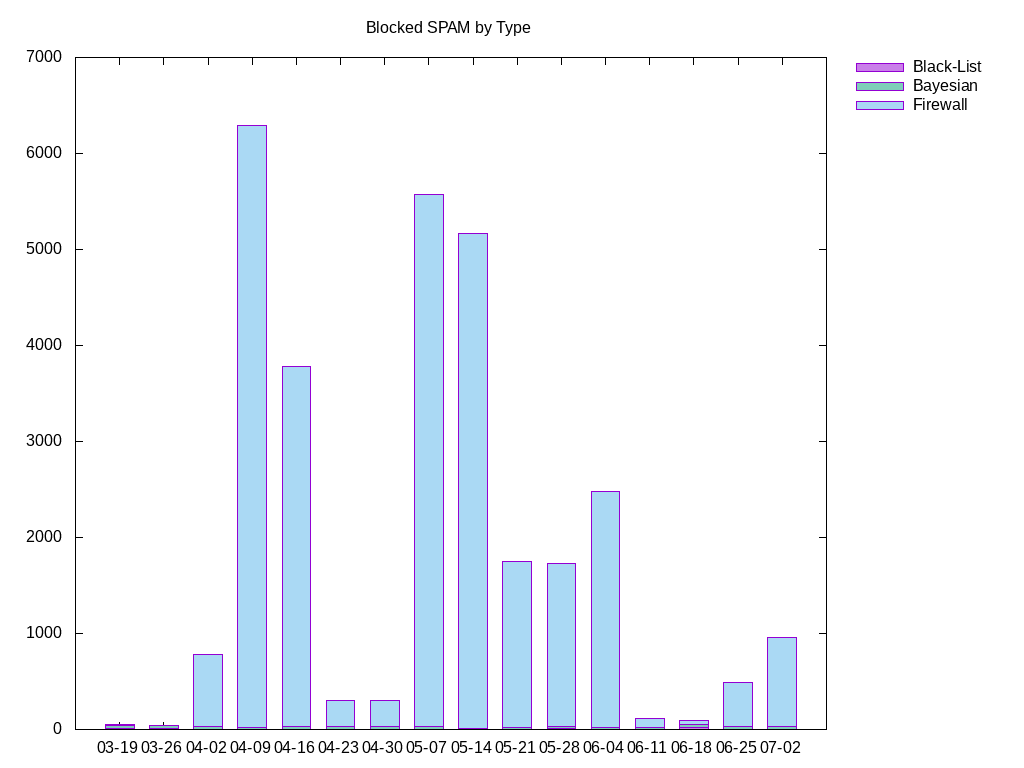
This graph shows the number of blocked emails per week, by type of blocking system, for the previous sixteen weeks.
The three blocking types of Firewall, Black-List and Bayesian are pipelined, with Firewall coming first, then Black-List blocking, ending with Bayesian filtering on those accounts that have enabled it.
Firewall blocking is the blocking of network addresses that belong to ISPs in countries that have poor MTA security, or who regularly allow SPAM to be sent from/through their servers. The firewall blocks Poland, China, Japan and Turkey. Firewall blocking does not just block the SPAM, it blocks access from the entire machine. From the point of view of a machine blocked by the firewall, the firewalled server is not network accessible.
Black-List blocking is the second blocking technique used in the pipeline. It checks the IP address of the originating MTA, and if that address is listed in one of the black lists currently configured into the MTA, that email is discarded, and a bounce message explaining why is sent back to the originator.
Bayesian filtering is last (hence its small contribution to the blocking statistics) and is only enabled per account. Bayesian filtering scans email headers and bodies for specific statistically significant signatures that have been created by "training" the filter. If a significant signature is detected, the offending email is automatically reported as SPAM to one of the black-lists. It is the reporting to a black list that is tallied for the SPAM histogram.
Consideration has been given to adding grey-listing to the SPAM mitigation technologies already in use. Grey listing consists of detecting the signature of a SPAM robot and, if present, refusing the proferred email. One risk of grey listing is that some non-standards compliant MTAs act like SPAM robots. Known good addresses can be pre-loaded into the white list data base, somewhat reducing the size of this problem, but nothing can be done to avoid false positives on new contacts from non-standards compliant MTAs.
The vertical axis is number of emails, the horizontal axis is month and day of the end of the reporting week.
John Stevens
john at betelgeuse dot us